
There are a lot of different methods of conducting research, and each comes with its own set of strengths and weaknesses. I've been thinking a lot about the various research approaches because I'm teaching a senior-level research methods class with a lab this spring. This has led me to think a lot about how these different research methodologies might work together. While most researchers are exposed to a variety of methodologies throughout graduate training, we tend to become engrossed with our own specialty. This makes sense, at least to me, as there are so many nuances that it can take years to become truly proficient in conducting research in our own areas. Specialization seems necessary; however, this is exactly why effective communication and collaboration is key. Given the strengths and weaknesses of different methodologies, a mixed method approach can be used to balance these strengths and weaknesses.
We have said many times before that "it takes a village" and open communication to solve large problems. When it comes to student learning, I feel strongly that it takes a diverse group of experts from different research backgrounds and various experiences teaching in schools. With the amount of time and dedication that it takes to become an expert researcher and an expert teacher, it would be hard for one person to become both! The same is true for research methodologies. There are pros and cons to each, and science is best served when we combine our efforts and tackle our questions from many different directions.

In this spirit, in today's blog I am writing about the general research methodologies that might be used to help us understand student learning. For each methodology, I describe what it is and how it might be used, as well as the strengths and weaknesses of the approach. This blog is a bit longer than our typical blogs because I'm tackling some big topics, but hopefully you'll find the discussion of various research methodologies, together in one place, as important as I do!
The main purpose of descriptive research is exactly what it sounds like it should be: to describe what is going on. There are a lot of individual approaches that fall under the descriptive research umbrella. Here are a few:
Case studies are a very in-depth analysis of an individual person, small group of people, or even an event. A researcher might conduct a case study on an individual who has a specific learning disability, or on a classroom that is engaging in a particular mode of instruction.
Observation research involves sitting back (so to speak) and watching how individuals interact in natural environments. A researcher might (with permission from the school and parents of the children, of course) watch a group of preschoolers through a 2-way mirror to see how the children interact with one another. There is also a special type of observation research called participatory observation. This method is used when it would be difficult or impossible to simply watch from a distance. You can think of this as going under cover, where the researcher joins a group to learn about the group. A classic example involves a researcher, Leon Festinger, who joined a cult who believed the world was going to be destroyed by a flood in the 1950s. From this work, Festinger proposed Cognitive Dissonance Theory (to read more, check out this page).
Survey research is considered descriptive research. In this work, the researcher compiles a set of questions and asks people to answer these questions. The types of questions can vary. Some surveys might people to rate their feelings or beliefs on a scale from 1-7 (also known as a "Likert" scale) or answer yes-no questions. Some surveys might ask more open-ended questions, and there are many that utilize a mix of these types of questions. If the researcher is asking a lot of open-ended questions, then we might call the research an interview, or a focus group if there are a few people discussing a topic and answering questions in a group. In this research, the participants may actually be guiding the direction of the research.
There is another important distinction to be made under the descriptive research umbrella: quantitative research vs. qualitative research. In quantitative research, data is collected in the forms of numbers. If a researcher asks a student to indicate on a scale from 1-10 how much they think they will remember from a lesson, then we are quantifying the student's perception of their own learning. In qualitative research, words are collected, and sometimes those words might be quantified in some way to use for statistical analysis. If a researcher asks a student to describe their learning process, or conducts in-depth interviews with teachers about classroom learning, then we are dealing with qualitative research.
Descriptive research can provide an in-depth view of any topic we might want to study, and the level of detail that we can find in descriptive research is extremely valuable. This is particularly true of descriptive research that is collected qualitatively. In this form of research, we may find information that we never even knew to look for! This type of research can be used to create new research questions, or form hypotheses about cause and effect relationships (though we cannot determine cause and effect from this research alone). Observation research has an added benefit of allowing us to see how things work in their natural environments.
We cannot determine a cause and effect relationship from descriptive research. For example, if a student talks about engaging with a particular learning strategy, and then provides an in-depth account of why they think it helped them learn, we cannot conclude that this strategy actually did help the student learn.
We also have to be very careful of reactivity in this type of research. Sometimes, people (and animals too) change their behavior if they know they're being observed. Similarly, in surveys we have to worry about participants providing responses that are considered desirable or in line with social norms. (For example, if a parent is asked, "did you ever smoke while pregnant with your child?" we have to worry about parents saying "no, never" because that is the more desirable answer, or the one that aligns with social norms.)
Correlational studies involve measuring two or more variables. For that reason, this research is inherently quantitative. The researchers can then look at how related to variables are to one another. If two variables are related, or correlated, then we can use one variable to predict the value of another variable. The greater the correlation, the greater accuracy our prediction will have. For example, correlational research might be able to tell us what factors at home are related to greater student learning in the classroom. These factors might include things like eating a healthy breakfast, getting enough sleep, having access to a lot of books, feeling safe, etc.
I often have my students think about car insurance to explain correlational research. Car insurance companies measure a lot of different variables, and then try to do their best to predict which customers are likely to cost them the most money (e.g., cause a car accident, have their car damaged, etc.). They know that on average younger males are more likely to cost them money, and that drivers who have received speeding tickets are more likely to cost them money. They also know that people living in certain areas are more likely to get into car accidents due to dense populations, or to have their car damaged while parked. Does this mean that a 16-year old boy who got a speeding ticket and lives in the city is definitely going to cause a car accident? No, of course not. Does this mean that getting a speeding ticket specifically causes later car accidents? No. It just means that the car insurance company knows that this type of person is more likely to cause the car accident, for any number of reasons, and uses this information to determine premiums.
Correlational research can help us understand the complex relationships between a lot of different variables. If we measure these variables in realistic settings, then we can learn more about how the world really works. This type of research allows us to make predictions, and can tell us if two variables are not related, and thus searching for a cause-effect relationship between the two is a huge waste of time.
Correlation is not the same as causation! Even if two variables are related to one another, that does not mean we can say for certain how the cause and effect relationship works. Take caffeine average consumption and average test. Lets say we find that the two are correlated, where increased caffeine is related to higher test performance. We cannot say that caffeine caused greater test performance, or that greater test performance caused greater caffeine consumption. In reality, either of those could work! For example, students may drink more caffeine and this might lead them to perform better on tests. Or, the students who perform better on tests are then more likely to drink more caffeine. A third variable could be related to both of these as well! It could be that students who are more concerned about their grades might study more and achieve better test performance, and might also drink more caffeine to help them stay awake to study! We just don't know from the correlation alone, but knowing that the two variables are in some way related can be very useful information.
True experiments involve manipulating (or changing) one variable and then measuring another. There are a few things that are required in order for research to be considered a true experiment. First, we need to randomly assign students to different groups. This random assignment helps create equivalent groups from the beginning. Second, we need to change something (for example, the type of learning strategy) across the two groups, holding everything else as constant as possible. The key here is to make sure to isolate the thing we are changing, so that it is the only difference between the groups. We also need to make sure at least one of the groups serves as a control group, or a group that serves as a comparison. We need to make sure that the only thing being systematically changed is our manipulation. (Note, sometimes we can systematically manipulate multiple things at once, but these are more complicated designs.) Finally, we then measure learning across the different groups. If we find that our manipulation led to greater learning compared to the control group, and we made sure to conduct the experiment properly with random assignment and appropriate controls, then we can say that our manipulation caused learning. Taking the example from the correlational section, if we want to know whether drinking coffee increases test performance, then we need to randomly assign some students drink coffee and other students to drink a non-caffeinated beverage (the control) and then measure test performance. And then, we repeat to be more confident in our conclusions! Usually, we're repeating experiments with little changes to continue obtaining new information.
Experiments can also be conducted in a “within-subjects” design. This means that each individual participating in the experiment is serving as their own control. In these experiments, each person participates in all of the conditions. To make sure that the order of conditions or materials are not affecting the results, the researcher randomizes the order of conditions and materials in a process called counterbalancing. The researcher then randomly assigns different participants to different versions of the experiment, with the conditions coming up in different orders. There are a number of ways to implement counterbalancing to maintain control in an experiment so that researchers can identify cause and effect relationships. The specifics of how to do this are not important for our purposes here. The important thing to note is that, even when participants are in within-subjects experiments and are participating in multiple learning conditions, in order to determine cause and effect we still need to maintain control and rule out alternate explanations for any findings (e.g., order or material effects).
This type of experiment allows us to determine cause and effect relationships! True experiments are often be designed based on descriptive research or correlational research to determine underlying causes. If we really want to know how to promote student learning in the classroom or at home, then we need to know what causes learning.
Of course, true experiments are not without weaknesses. True experiments require a lot of control so that we can isolate the variables that are causing changes to occur. The more control we have, the better measurement we have. However, at the same time, the more control we have, the more artificial the experiment becomes. Just because we that a learning strategy causes learning in one specific experiment, doesn't mean that it will work the same way with different types of students, or in live classroom settings. In other words, the effect might not be generalizable. The solution to this problem is to approach the question with a number of different experiments, and to include the other research approaches to get a better picture of what is going on. One way we've tried to do this in research about learning is to utilize the lab to classroom model.
What is one solution to the big weakness associated with true experiments? Do a bunch more experiments! Not just any experiments, of course, but experiments that, together, help combat the weaknesses described above. When we talk about the lab to classroom model*, we are talking primarily about true experiments. In the lab to classroom model, we start out with basic, highly controlled experiments in very artificial settings. This allows us to best determine cause and effect relationships. We then slowly work our way up to the more realistic setting. We lose control when we do this, and it is more difficult to determine cause and effect, but when we take all of the experimental evidence together we can be much more confident in our conclusions!
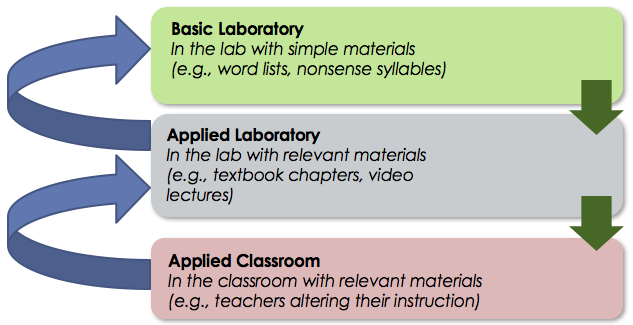
* If you're not familiar with the lab to classroom model, see this blog for a brief description, or listen to this podcast to hear Yana and I talk about the model.
Finally, there is one design that you might see pop up here and there, and it has so many problems that it's worth mentioning explicitly. Pre-test post-test designs are exactly like what they sound like: you measure something before an intervention and after the intervention, and compare. This is not a true experiment, and does not allow us to determine cause and effect relationships.
For example, you might (unfortunately) see someone provide students with a pre-test to assess prior knowledge, then implement some sort of learning strategy, and then provide students with a post-test to see how much they have learned (compared to the pre-test). This design is extremely problematic! We truly have no idea whether the learning intervention caused any learning in this case. It could be that the students just got better over time, or that they learned from taking the pre-test, or that because they knew they were being tested before and after they were more likely to study at home! We cannot say the learning strategy did anything for certain. Using pre-tests and post-tests in research is acceptable, but only if there is a control group for comparison!
While not all methodologies discussed in this blog allow us to determine cause and effect, but they have other strengths that go along with them. This design does not allow us to infer causality, nor does it give us the in-depth, detailed information we get from descriptive research, nor does it tell us the relationships among many different variables!